The emergence of ChatGPT search has led to many questions about the quality of the overall results compared to Google.
This is a difficult question to answer, and in today’s article, I will provide some insights into how to do just that.
Note that our understanding is that the technology that makes it possible for OpenAI to offer a search capability is called SearchGPT, but the actual product name is ChatGPT search.
In this article, we will use the name ChatGPT search.
What’s in this report
This report presents an analysis of 62 queries to assess the strengths and weaknesses of each platform.
Each response was meticulously fact-checked and evaluated for alignment with potential user intents.
The process, requiring about an hour per query, highlighted that “seemingly good” and “actually good” answers often differ.
Additionally, when Google provided an AI Overview, it was scored against ChatGPT search.
A combined score for the AI Overviews and the rest of Google’s SERP was also included.
Of the queries tested – two-thirds of which were informational – Google returned an AI Overview in 25 instances (40% of the time).
The queries analyzed fell into multiple categories:
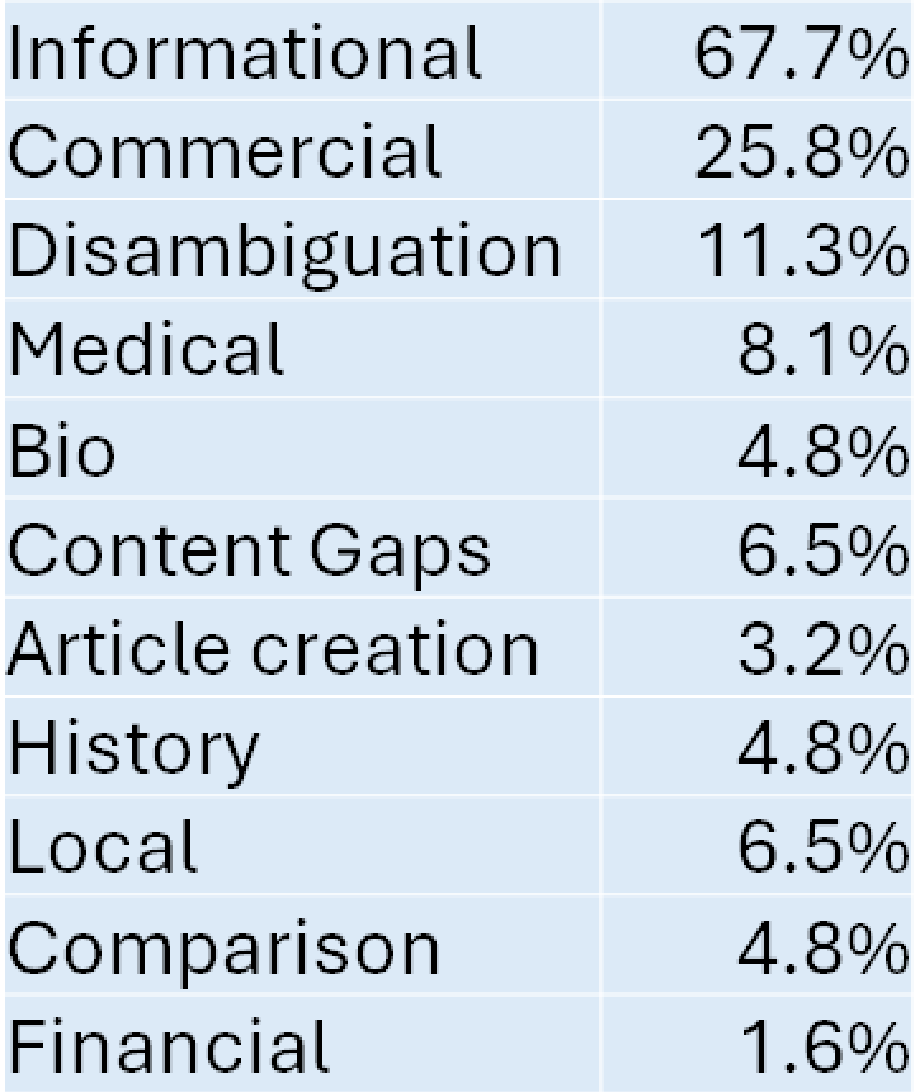
The total number of the above is greater than 100%, and that’s because some queries could fall into more than one classification.
For example, about 13% of the queries were considered informational and commercial.
Detailed information from SparkToro on the makeup of queries suggests a natural distribution of search queries as follows:
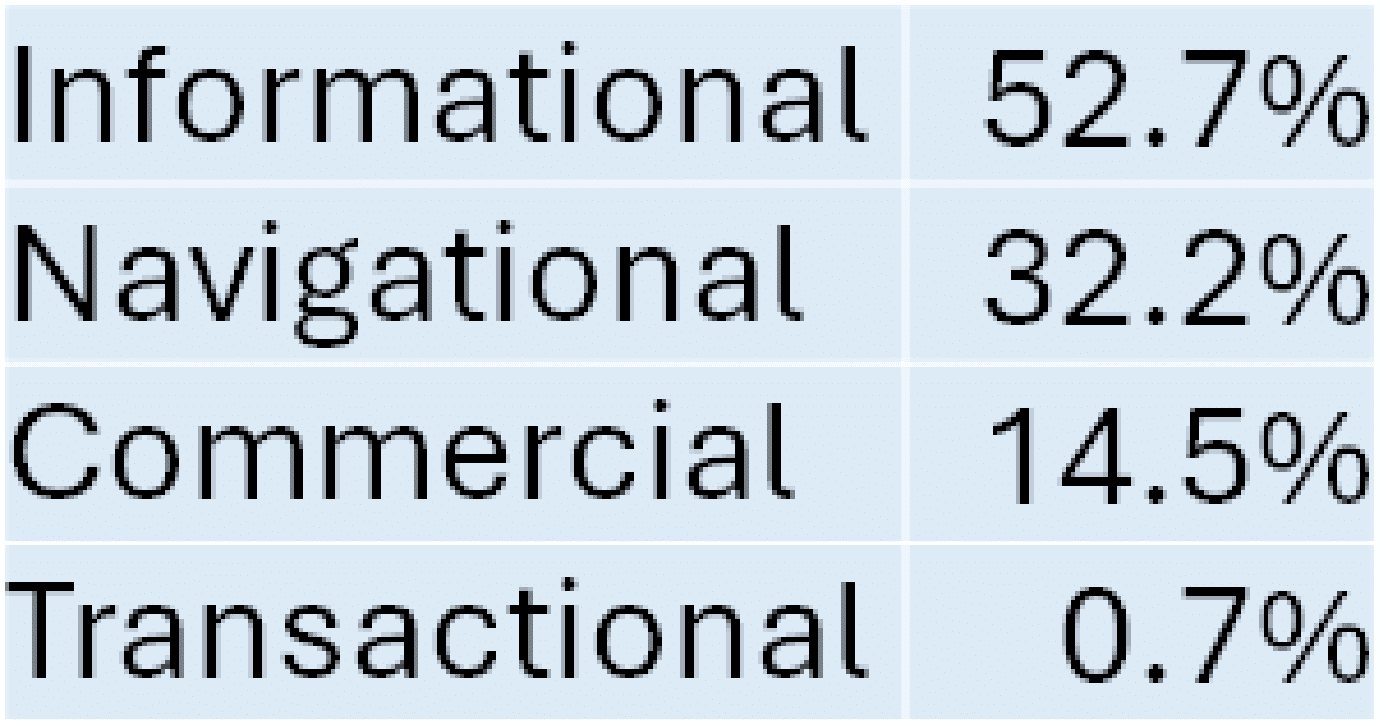
Navigational queries, which comprise nearly a third of all queries, were excluded from this test.
These queries typically demand a straightforward response like, “just give me the website,” and are a category where Google excels.
However, I included queries likely to favor one platform, such as:
- Content gap analysis queries (4): Representing a broader class of content-related queries, which Google doesn’t handle but ChatGPT search attempts (though not always successfully).
- Locally oriented queries (4): These leverage Google’s extensive local business database, Google Maps, and Waze, areas where ChatGPT search struggles to compete.
Metrics used in this study
I designed 62 queries to reflect diverse query intents, aiming to highlight each platform’s strengths and weaknesses.
Each response was scored across specific metrics to evaluate performance effectively.
- Errors: Did the response include incorrect information?
- Omissions: Was important information not in the response?
- Weaknesses: Were other aspects of the response considered weak but not scored as an error or omission?
- Fully addresses: Was the user’s query intent substantially addressed?
- Follow-up resources: Did the response provide suitable resources for follow-up research?
- Quality: An assessment by me of the overall quality of the response. This was done by weighing the other factors contained in this list.
At the end of this article are the total scores for each platform across the 62 queries.
Competitive observations
When considering how different search platforms provide value, it’s important to understand the many aspects of the search experience. Here are some of those areas:
Advertising
Multiple reviewers note that ChatGPT search is ad-free and tout how much better this makes it than Google. That is certainly the case now, but it won’t stay that way.
Microsoft has $13 billion committed to OpenAI so far, and they want to make that money back (and then some).
In short, don’t expect ChatGPT search to remain ad-free. That will change significantly at some point.
An important note is that advertising works best on commercial queries.
As you will see later in this article, I scored Google’s performance on commercial queries significantly higher than ChatGPT search.
Understanding user intent
Google has been working on understanding user intent across nearly infinite scenarios since 2004 or earlier.
They’ve been collecting data based on all the user interactions within search and leveraging what they have seen with the Chrome browser since its launch in 2008.
This data has most likely been used to help train Google algorithms to understand user intent and brand authority on a per query basis.
For reference, as of November 2024, Statcounter pegs Chrome’s market share at 67.5%, Safari at 18.2%, and Edge at 4.8%
This is a critical advantage for Google because understanding the user intent of a query is what it’s all about.
You can’t possibly answer the user’s need without understanding their need. As I’ll illustrate in the next section, this is complex!
How query sessions work
Part of the problem with understanding user intent is that the user may not have fully worked out what they’re looking for until they start the process.
Consider the following example of a query sequence that was given to me via Microsoft many years ago:
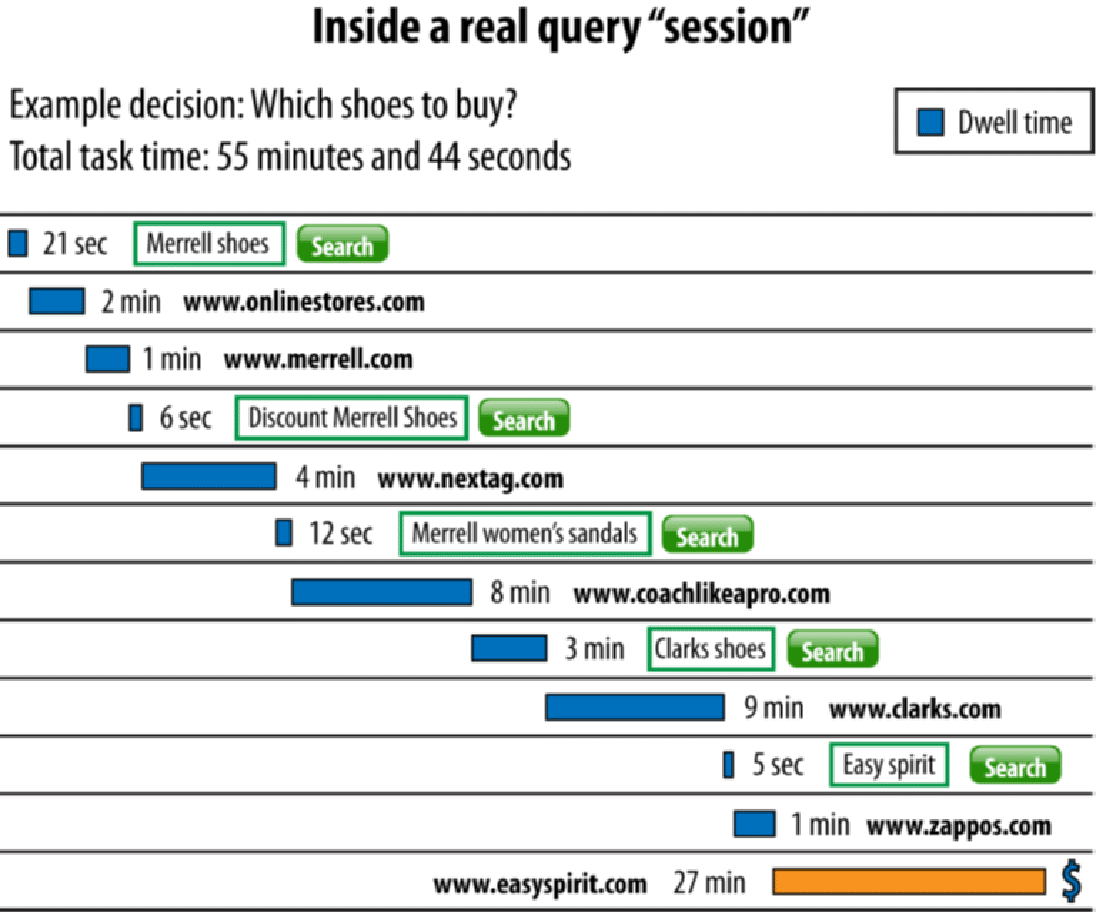
The initial query seems quite simple: “Merrell Shoes.”
You can imagine that the user entering that query often has a specific Merrell shoe in mind, or at least a shoe type, that they want to buy.
However, we see this user’s path has many twists and turns.
For example, the second site they visit is www.merrell.com, a website you might suspect has authoritative information about Merrell shoes.
However, this site doesn’t appear to satisfy the user’s needs.
The user ends up trying four more different queries and visiting six different websites before they finally execute a transaction on www.zappos.com.
This degree of uncertainty in search query journeys is quite common.
Some of the reasons why users have this lack of clarity include is that they:
- Don’t fully understand the need that they’re feeling.
- Don’t know how to ask the right questions to address their need.
- Need more information on a topic before deciding what they need.
- Are in general exploration mode.
Addressing this is an essential aspect of providing a great search experience. This is why the Follow-Up Resources score is part of my analysis.
Understanding categories of queries
Queries can be broadly categorized into several distinct groups, as outlined below:
- Informational: Queries where the user wants information (e.g., “what is diabetes?”).
- Navigational: Queries where the user wants to go to a specific website or page (e.g., “United Mileage Club”).
- Commercial: Queries where the user wants to learn about a product or service (e.g., “Teak dining table”).
- Transactional: Queries where the user is ready to conduct a transaction (e.g., “pizza near me”).
Recent data from SparkToro’s Rand Fishkin provides some insight into the percentage of search queries that fall into each of these categories:
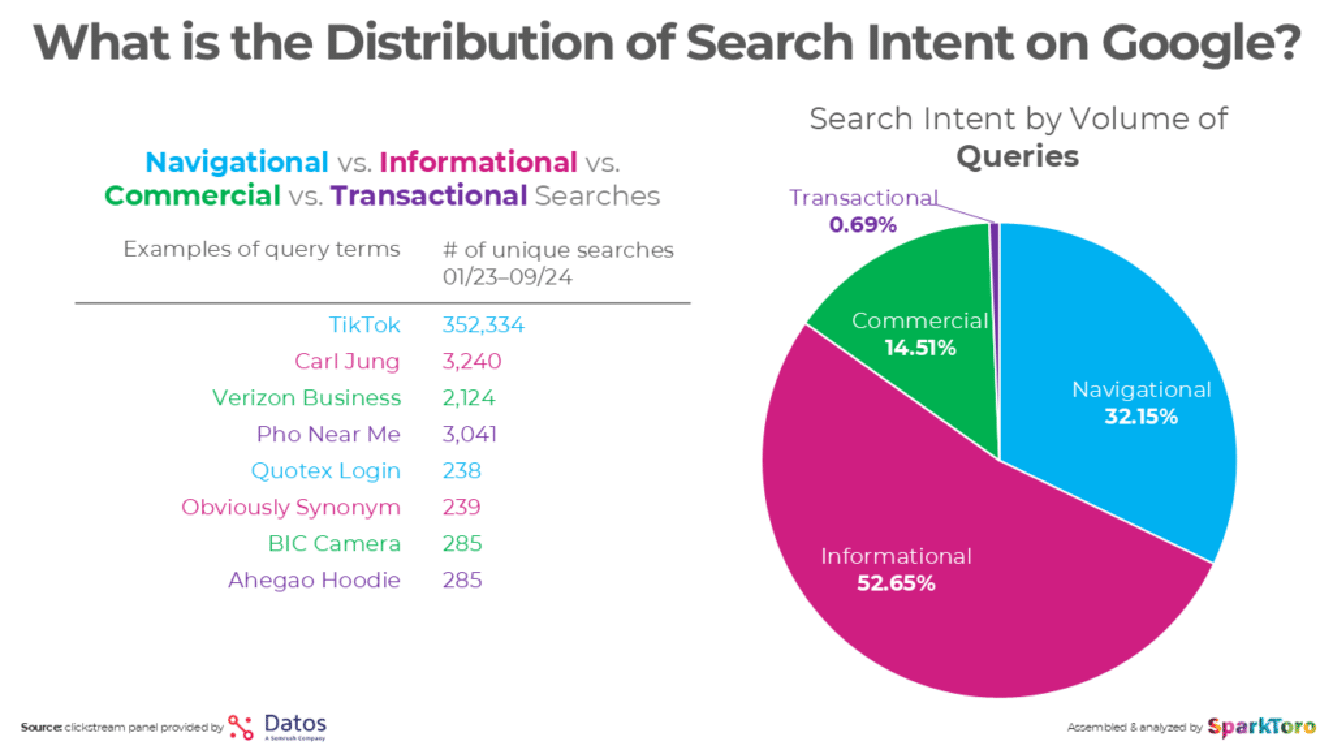
Be advised that the above is a broad view of the categories of queries.
The real work in search relates to handling searches on a query-by-query basis. Each query has many unique aspects that affect how it can be interpreted.
Next, we’ll examine several examples to illustrate this. Then, we’ll compare how ChatGPT search and Google performed on these queries.
Query type: Directions
This query type is a natural strength for Google (as is any locally oriented query). We can see ChatGPT search’s weaknesses in this area in its response:

The problems with this response are numerous.
For example, I wasn’t in Marlborough, Massachusetts, when I did the query (I was in the neighboring town of Southborough).
In addition, steps 1 and 2 in the directions are unclear. Anyone following them and heading east on Route 20 would end up at Kenmore Square in Boston without ever crossing I-90 East.
In contrast, Google nails it:
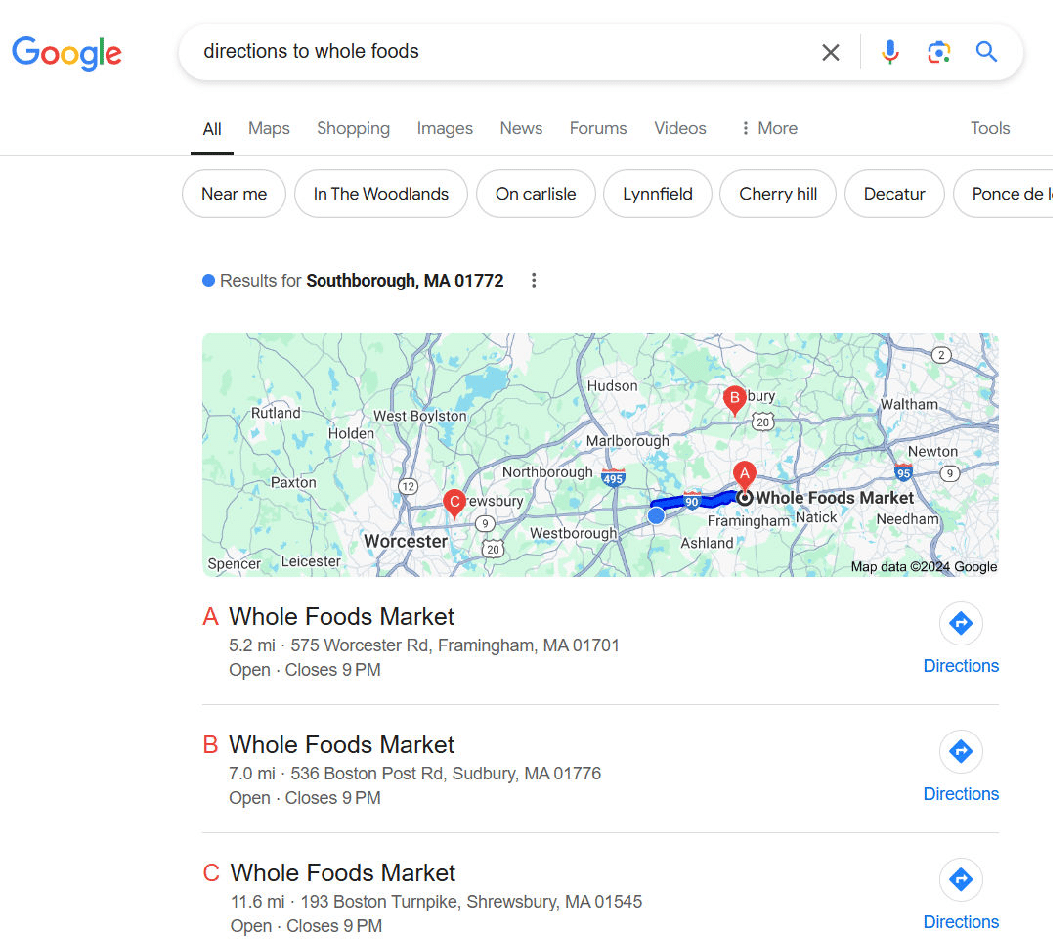
The reason why Google handles this better is simple.
Google Maps has an estimated 118 million users in the U.S., and Waze adds another 30 million users.
I wasn’t able to find a reasonable estimate for Bing Maps, but suffice it to say that it’s far lower than Google’s.
The reason Google is so much better than Bing here is simple – I use Google Maps, and that lets Google know exactly where I am.
This advantage applies to all Google Maps and Waze users in the U.S.
Query type: Local
Other types of local queries present similar issues to those of ChatGPT search. Note that a large percentage of search queries have local intent.
One estimate pegged this at 46% of all queries. This was reportedly shared by a Googler during a Secrets of Local Search conference at GoogleHQ in 2018.
Here is ChatGPT’s response to one example query that I tested:
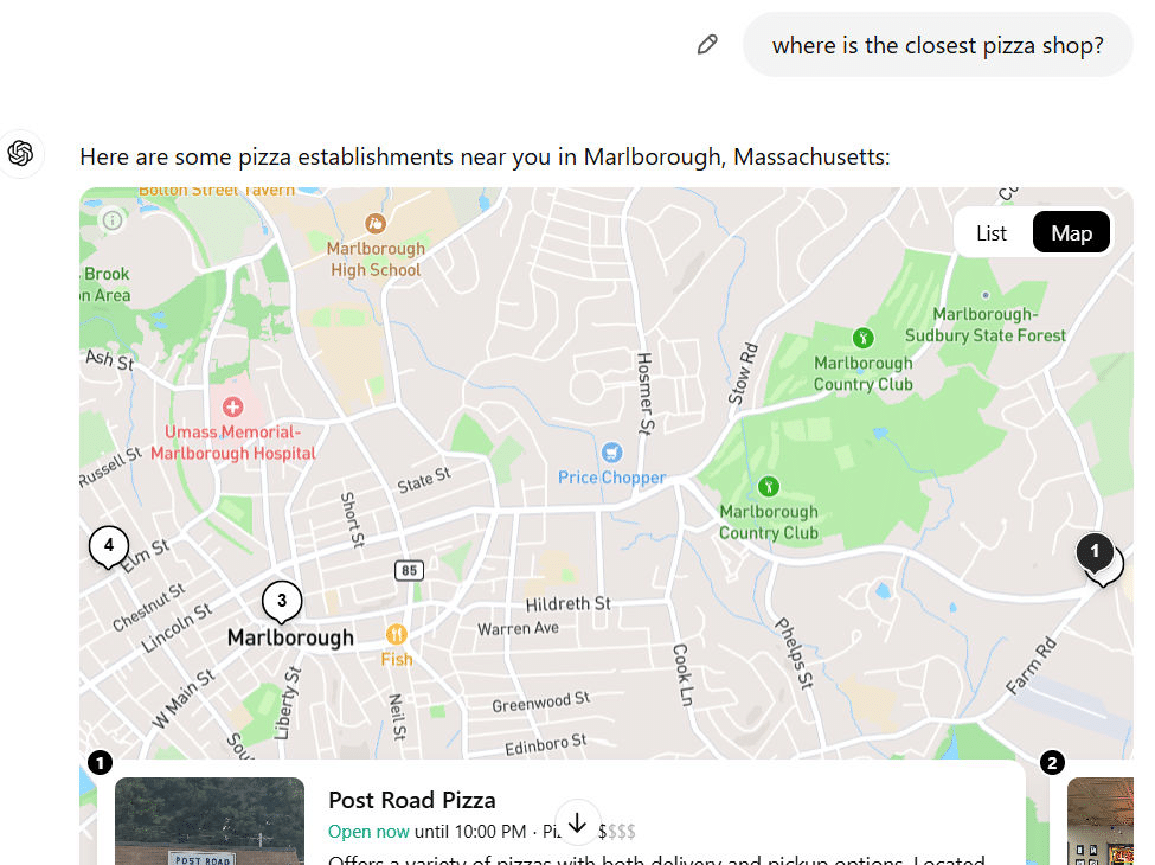
As with the directions example, it thinks that I’m in Marlborough.
In addition, it shows two pizza shops in Marlborough (only one of the two is shown in my screenshot).
Google’s response to this query is much more on point:

I also gave Google a second version of the query “Pizza shops in Marlborough,” and it returned 11 locations – 9 more than I saw from the ChatGPT search.
This shows us that Google also has far more access to local business data than ChatGPT search.
For this query class (including the Directions discussed previously), I assigned these scores:
- ChatGPT search: 2.00.
- Google: 6.25.
Query type: Content gap analysis
A content gap analysis is one of the most exciting SEO tasks that you can potentially do with generative AI tools.
The concept is simple: provide the tool of your choice a URL from a page on your site that you’d like to improve and ask it to identify weaknesses in the content.
As with most things involving generative AI tools, it’s best to use this type of query as part of a brainstorming process that your subject matter expert writer can use as input to a larger process they go through to update your content.
There are many other different types of content analysis queries that you can do with generative AI that you can’t do with Google (even with AI Overviews) at this point.
For this study, I did four content gap analysis queries to evaluate how well ChatGPT search did with its responses.
Google presented search results related to the page I targeted in the query but did not generate an AI Overview in any of the four cases.
However, ChatGPT search’s responses had significant errors for three of the four queries I tested.
Here is the beginning of ChatGPT search’s response to the one example query where the scope of errors was small:

This result from ChatGPT isn’t perfect (there are a few weaknesses, but it’s pretty good. The start of Google’s response to the same query:
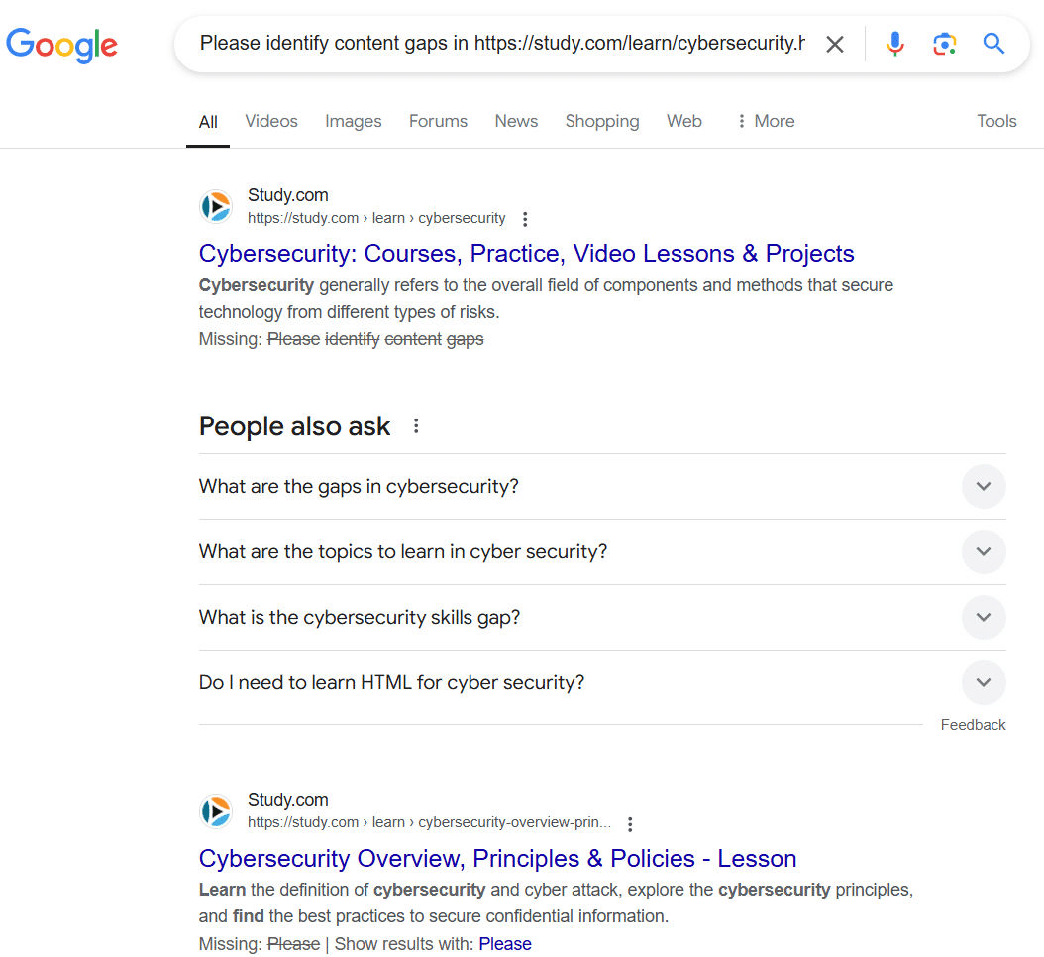
As you can see, Google hasn’t even attempted to perform a content gap analysis. ChatGPT search is better set up to address this type of query.
However, ChatGPT search doesn’t earn a clean sweep for this type of query.
Here is the first part of another example result:

This looks good in principle, but it’s filled with errors. Some of these are:
- The Britannica article does discuss the depth of Larry Bird’s impact on Indiana State University.
- The Britannica article does mention the importance of the Larry Bird / Magic Johnson rivalry to the NBA
- The ChatGPT search response is longer than shown here and there are other errors beyond what I mention here.
Overall, I tried four different content gap analysis queries and ChatGPT search made significant errors in three of them. For this query, I assigned these scores:
- ChatGPT search: 3.25.
- Google: 1.00.
Query type: Individual bio
How these queries perform is impacted by how well-known the person is.
If the person is very famous, such as Lionel Messi, there will be large volumes of material written about them.
If the amount of material written about the person is relatively limited, there is a higher probability that the published online information hasn’t been kept up to date or fact-checked.
We see that in the responses to the query from both ChatGPT search and Google.
Here is what we see from ChatGPT search:
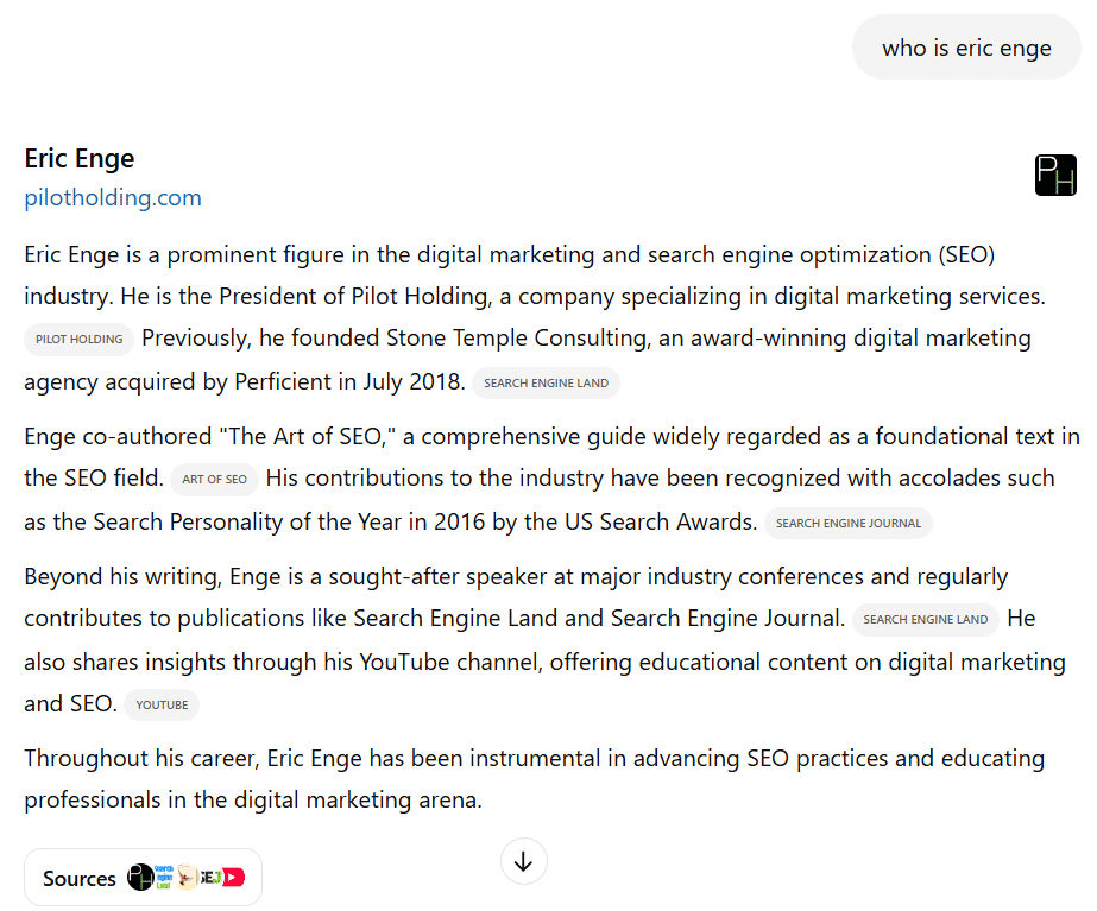
The main issues with this response are in the third paragraph.
I haven’t written for Search Engine Journal in a long time, and it’s also been more than six years since I published a video on my YouTube channel (@stonetemplecons).
Let’s see what Google has to say:
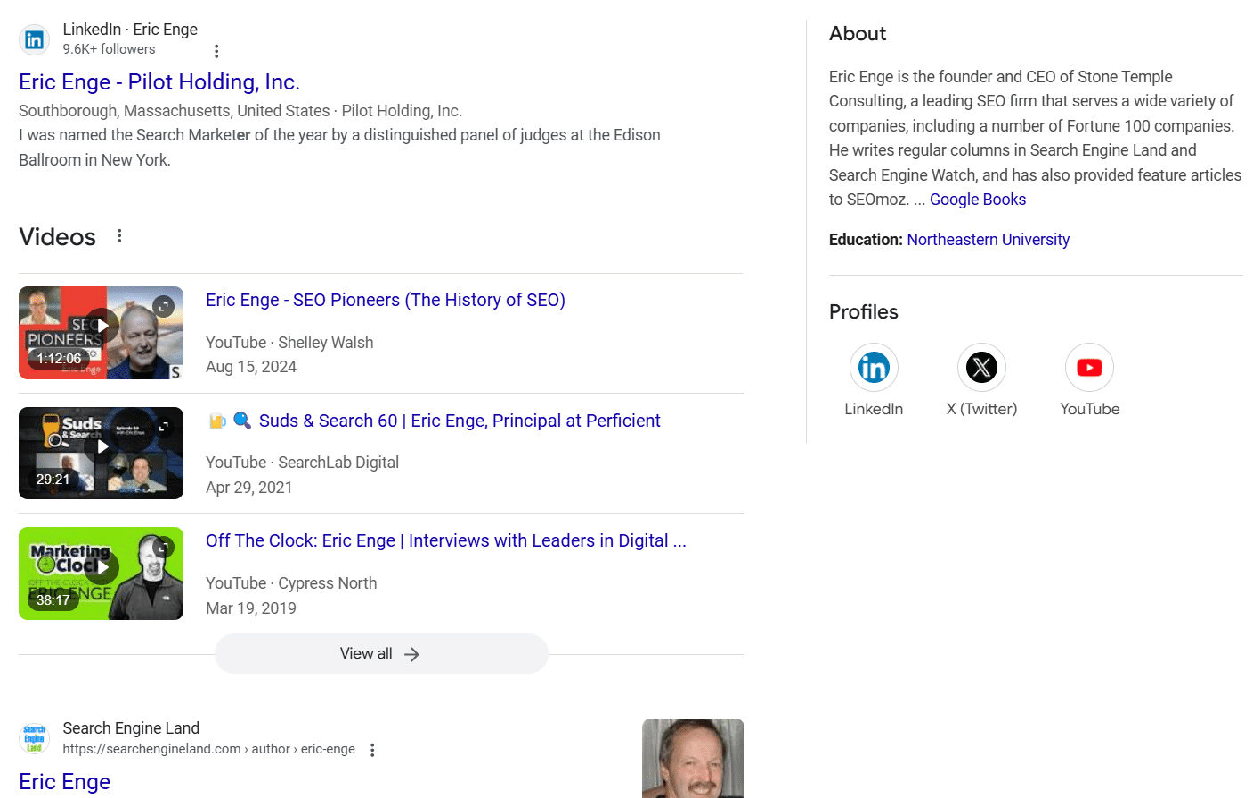
Google also has problems with its response. They lead with quite a few images of me (which are all accurate), and below that, they show my LinkedIn profile and a summary of me drawn from Google Books.
Here, it says that I write for Search Engine Watch (haven’t done that for more than a decade!) and SEOMoz (which rebranded to SEOmoz to Moz in 2013) (also more than a decade!).
These responses are both examples of what I call “Garbage-In-Garbage-Out” queries.
If the web sources aren’t accurate, the tools don’t have the correct information to render.
For bio queries (3 of them), I scored the competitors as follows:
- ChatGPT search: 6.00.
- Google: 5.00.
Query type: Debatable user intent
Arguably, nearly every search query has debatable user intent, but some cases are more extreme than others.
Consider, for example, queries like these:
- Diabetes.
- Washington Commanders.
- Physics.
- Ford Mustang.
Each of these examples represents an extremely broad query that could have many different intents behind it.
In the case of diabetes:
- Does the person just discover that they have (or a loved one has) diabetes, and they want a wide range of general information on the topic?
- Are they focused on treatment options? Long-term outlook? Medications? All of the above?
Or, for a term like physics:
- Do they want a broad definition of what it’s about?
- Or is there some specific aspect of physics that they wish to learn much more about?
Creating the best possible user experience for queries like these is tricky because your response should provide opportunities for each of the most common possible user intents.
For example, here is how ChatGPT responded to the query “physics”:

The additional two paragraphs of the response focused on the definition of Physics and kept the response at a very high level.
In contrast, the beginning of Google’s response also focuses on a broad definition of physics, but following that are People Also Ask and Things to Know boxes that address many other potential areas of interest to people who type in this search query:
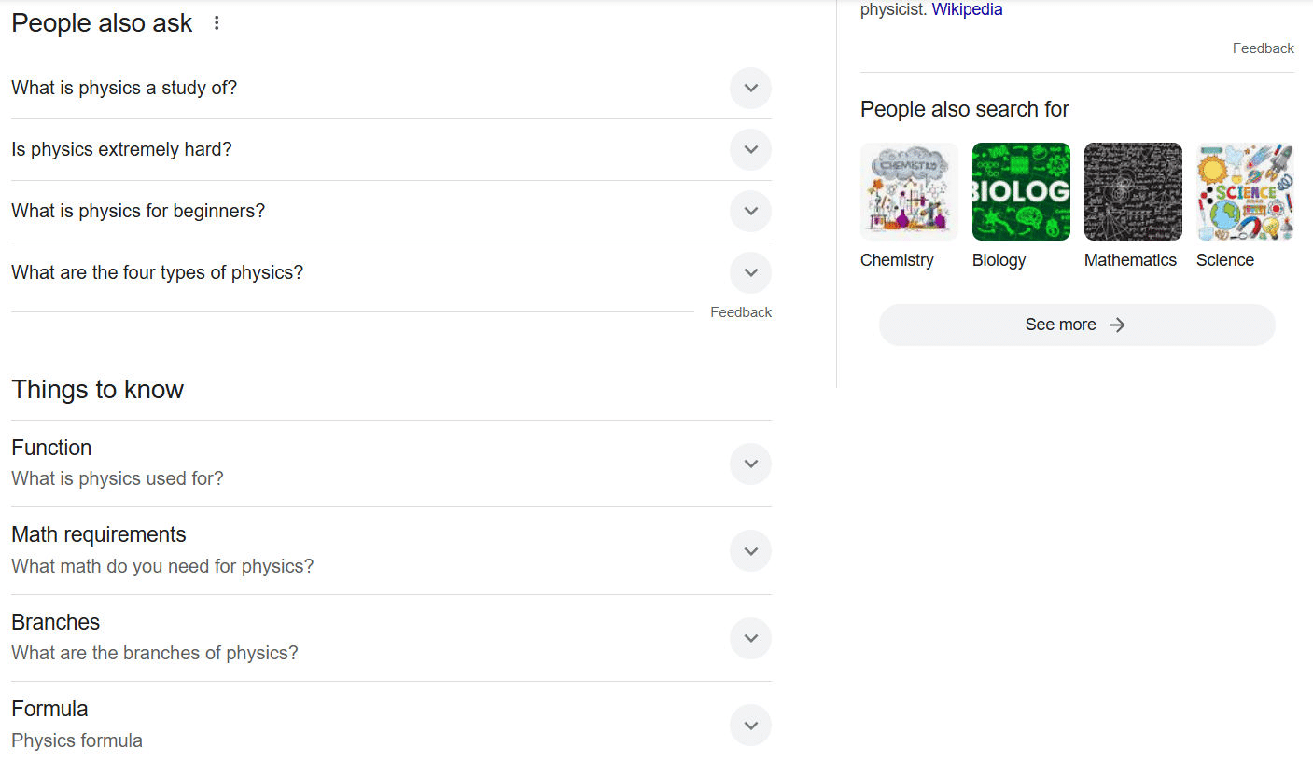
This part of Google’s response shows a recognition of the many possible intents that users who type in the phrase “physics” may have in mind.
For this query, I assigned these scores:
- ChatGPT search: 5.00.
- Google: 7.00.
Query type: Disambiguation
One special class of debatable intents queries is words or phrases that require disambiguation. Here are some example queries that I included in my test set:
- Where is the best place to buy a router?
- What is a jaguar?
- What is mercury?
- What is a joker?
- What is a bat?
- Racket meaning.
For example, here is how ChatGPT search responded to the question, “What is a joker query?”

We can see that it offers a nice disambiguation table that provides a brief definition for five different meanings of the term.
It also includes links to pages on the web that users can visit for information related to each meaning.
In contrast, Google focuses on two major intents:
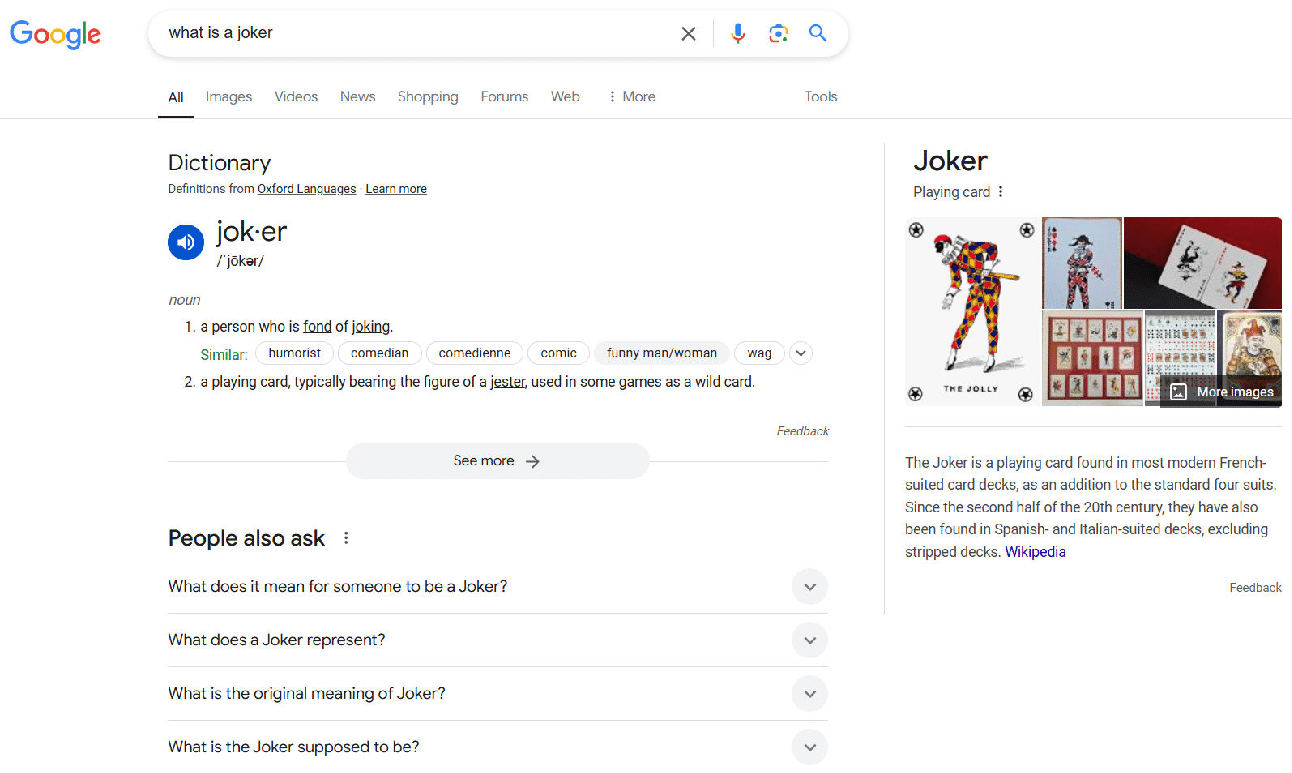
Google’s focus is on the playing card and a person who tells a lot of jokes.
Following this part of the SERP, Google continues this approach with websites focusing on these two definitions.
This means that someone who’s interested in the word “joker” as it applies to contract clauses will have to do an additional search to find what they were looking for (e.g., “meaning of joker when referring to contract clauses”).
Which is better?
Well, it depends.
If the searchers interested in playing cards or people who tell lots of jokes make up more than 90% of the people who enter this search query, then the Google result might be the better of the two.
As it is, I scored the ChatGPT search result a bit higher than Google’s for this query.
Another example of disambiguation failure is simply not addressing it at all. Consider the query example: “where is the best place to buy a router?”
Here is how ChatGPT search addressed it:
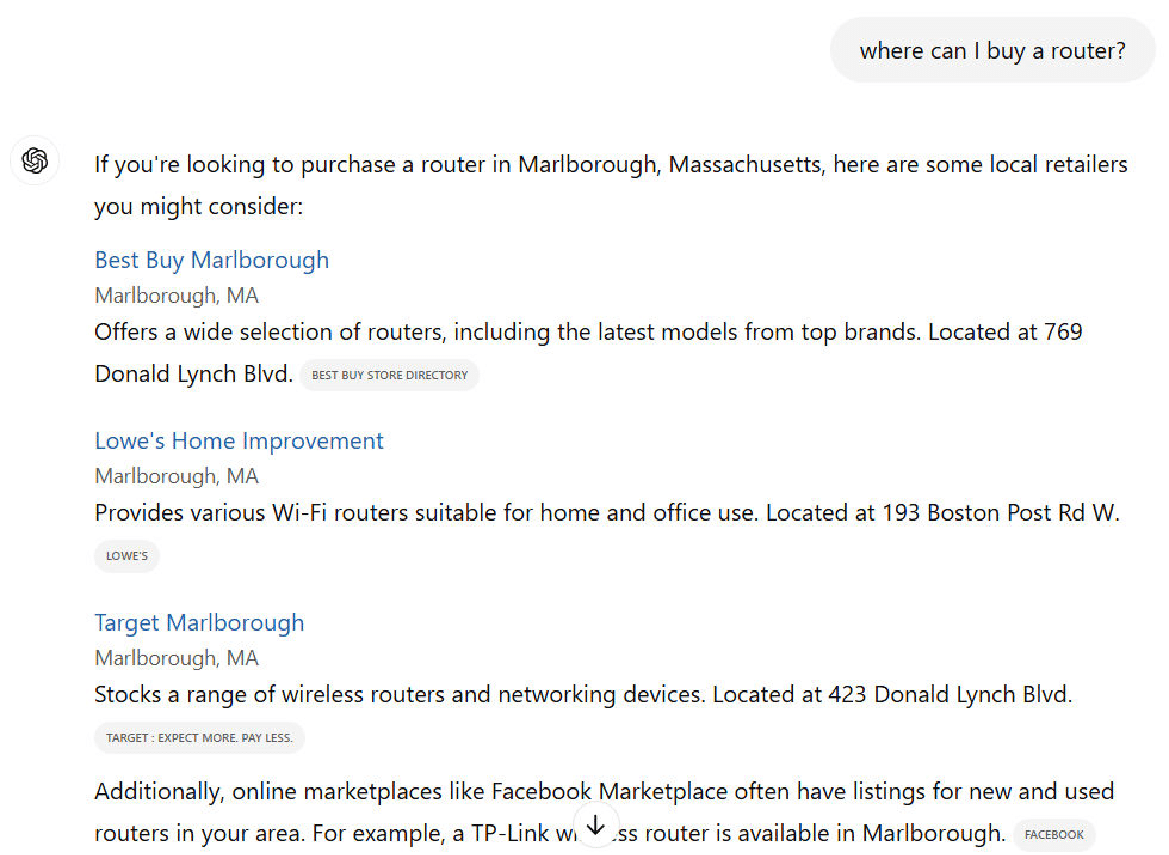
You might think this result is perfect, but routers also refer to a tool used in woodworking projects.
I use one frequently as a part of building furniture from scratch (true story).
There is a large enough audience of people who use these types of routers that I hope to see recognition of this in the SERPs.
Here is Google’s response to the query:
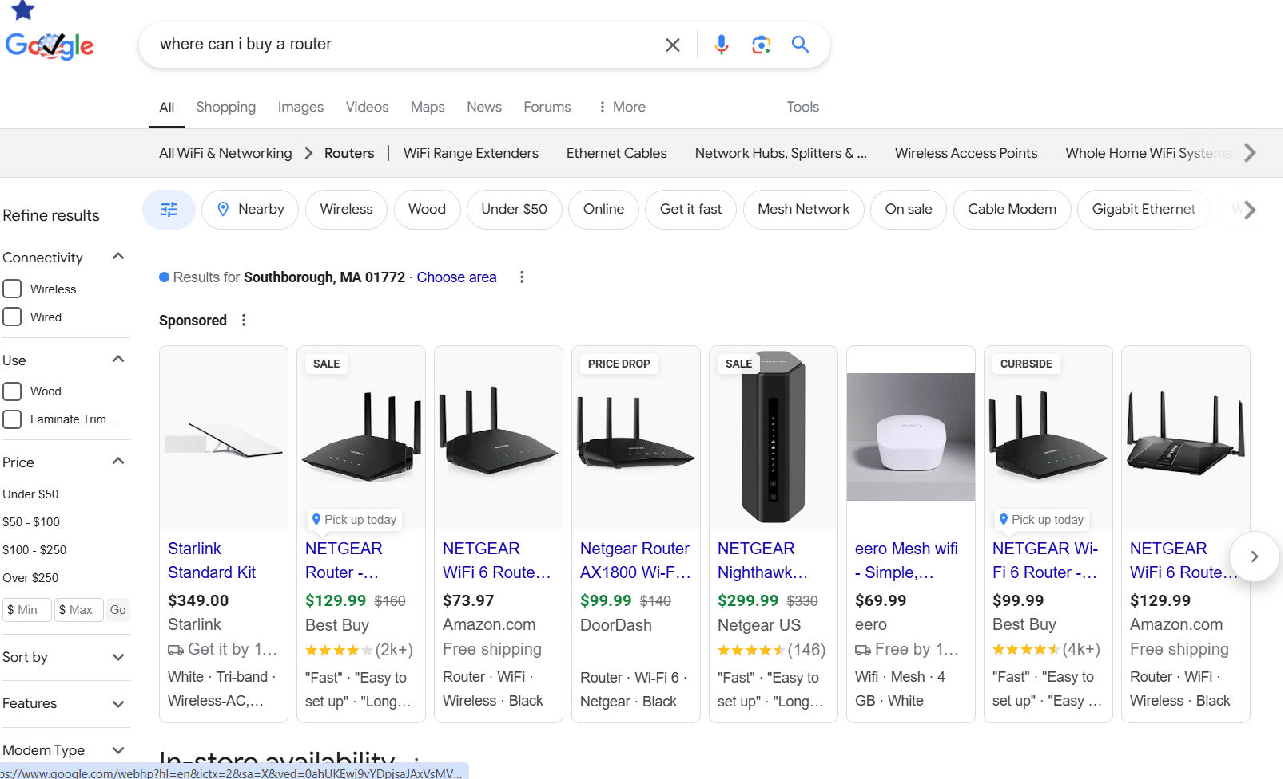
This part of the SERP is followed by:
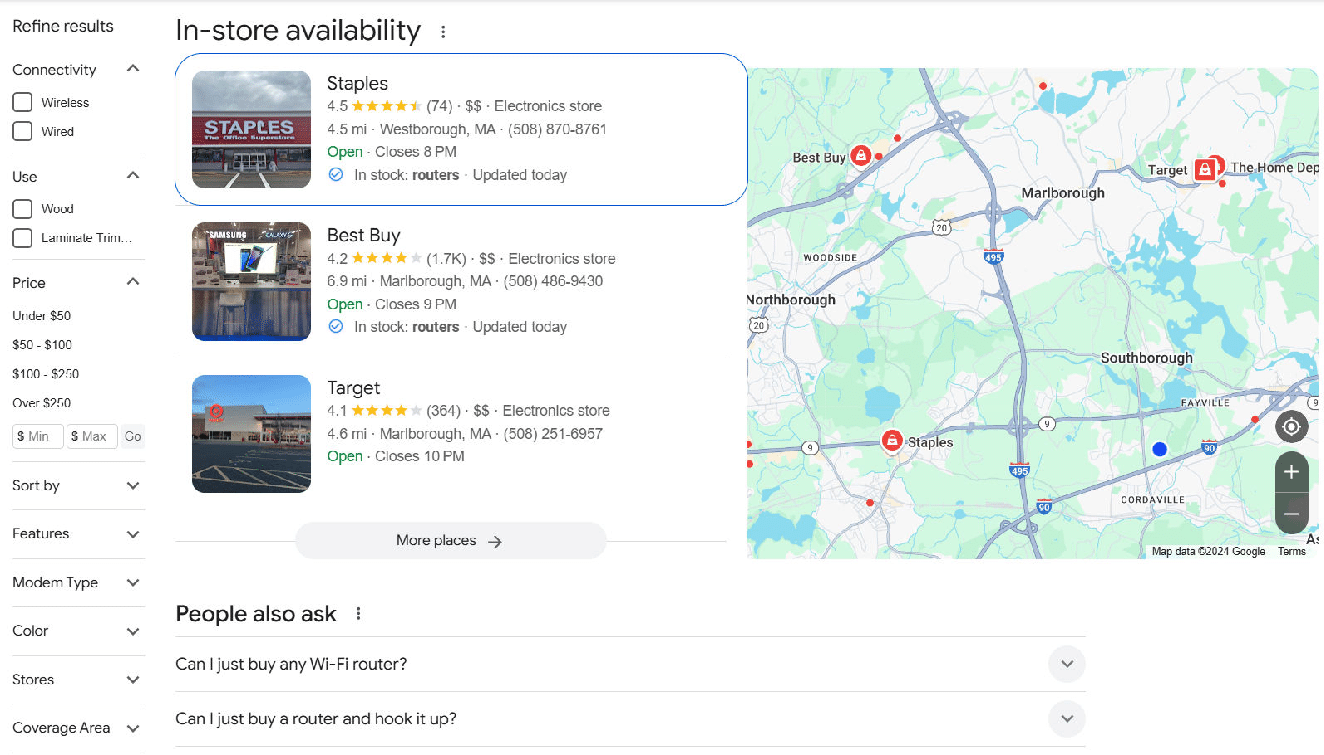
Google focuses on the internet router to the same degree as ChatGPT.
For this class of queries, I assigned these scores:
- ChatGPT search: 6.00.
- Google: 5.29.
Query type: Maintaining context in query sequences
Another interesting aspect of search is that users tend to enter queries in sequences.
Sometimes those query sequences contain much information that helps clarify their query intent.
An example query sequence is as follows:
- What is the best router to use for cutting a circular table top?
- Where can I buy a router?
As we’ve seen, the default assumption when people speak about routers is that they refer to devices for connecting devices to a single Internet source.
However, different types of devices, also called routers, are used in woodworking.
In the query sequence above, the reference to cutting a circular table should make it clear that the user’s interest is in the woodworking type of router.
ChatGPT’s response to the first query was to mention two specific models of routers and the general characteristics of different types of woodworking routers.
Then the response to “where can I buy a router” was a map with directions to Staples and the following content:
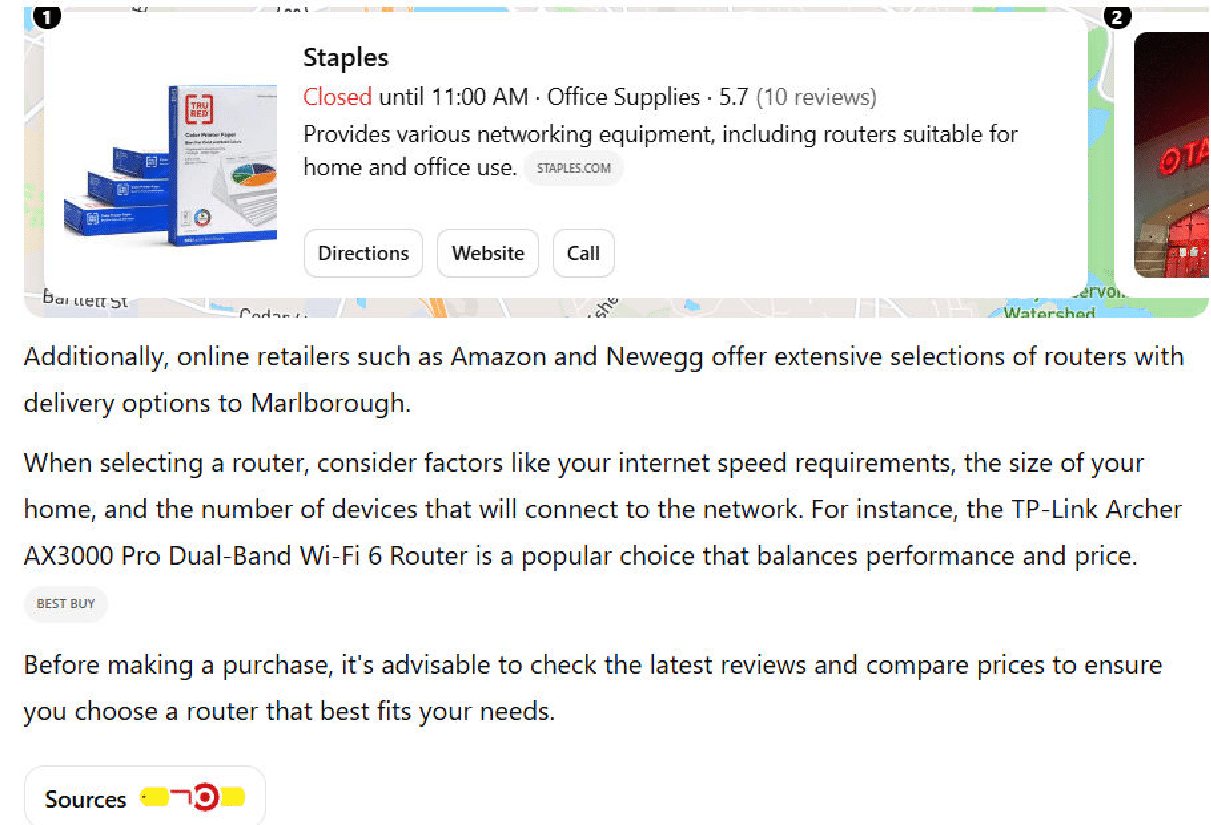
All of the context of the query was 100% lost.
Sadly, Google only performed slightly better.
It identified three locations, two of which were focused on networking routers and one which was focused on woodworking routers (Home Depot):
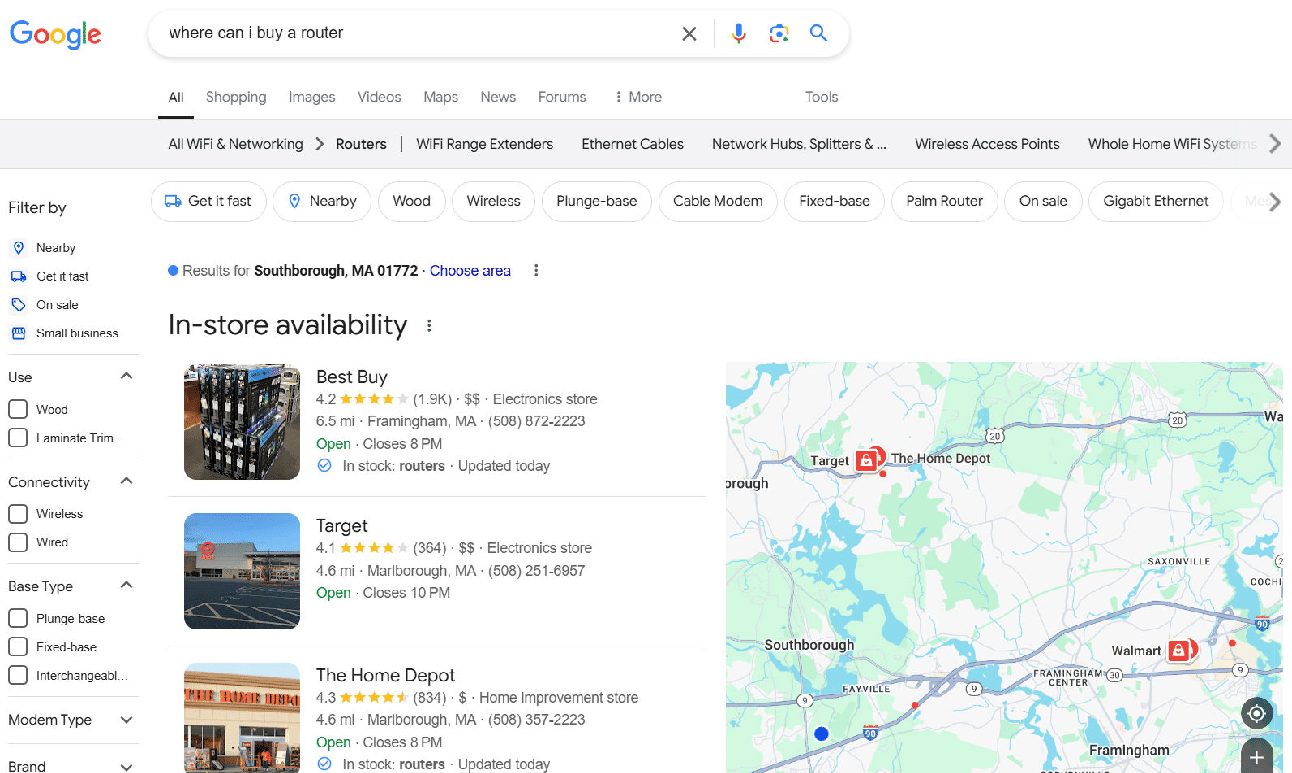
For this query, I scored the tools this way:
- ChatGPT search: 2.00.
- Google: 3.00.
Query type: Assumed typos
Another interesting example is queries where your search is relatively rare, yet it has a spelling that’s similar to another word.
For this issue, my search was: “Please discuss the history of the pinguin.”
The Pinguin was a commerce raider used by the German Navy in World War 2. It just has a spelling very similar to “penguin,” which is an aquatic flightless bird.
Both ChatGPT and Google simply assumed that I meant “penguin” and not “pinguin.”
Here is the result from ChatGPT:

The result continues after what I’ve shown here but continues to focus on the bird, not the boat.
Google makes the same mistake:
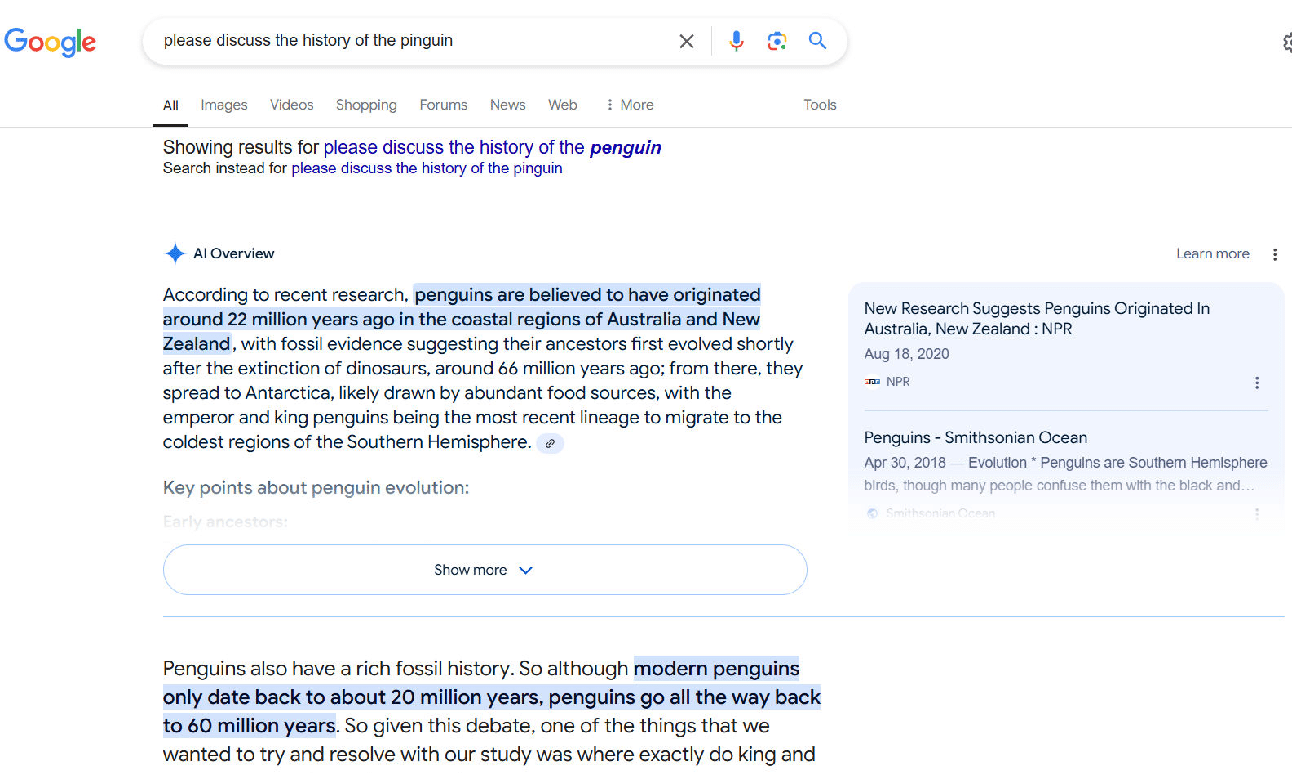
After the AI Overview and the featured snippet I’ve shown here, the SERPs continue to show more results focused on our flightless friends.
To be fair, I’ve referred to this as a mistake, but the reality is that the percentage of people who enter “pinguin” that simply misspelled “penguin” is probably far greater than those who actually mean the German Navy’s WW2 commerce raider.
However, you’ll notice that Google does one thing just a touch better than ChatGPT here.
At the top of the results, it acknowledges that it corrected “pinguin” to “penguin” and allows you to change it back.
The other way I addressed the problem was to do a second query: “Please discuss the history of the pinguin in WW2,” and both ChatGPT and Google gave results on the WW2 commerce raider.
For this query, I assigned these scores:
- ChatGPT search: 2.00.
- Google: 3.00.
Query type: Multiple options are a better experience
There are many queries where a single (even if it is well thought out) response is not what someone is probably looking for.
Consider, for example, a query like: “smoked salmon recipe.”
Even though the query is in the singular, there is little chance that anyone serious about cooking wants to see a single answer.
This type of searcher is looking for ideas and wants to look at several options before deciding what they want to do.
They may want to combine ideas from multiple recipes before they have what they want.
Let’s look at the response from ChatGPT search:
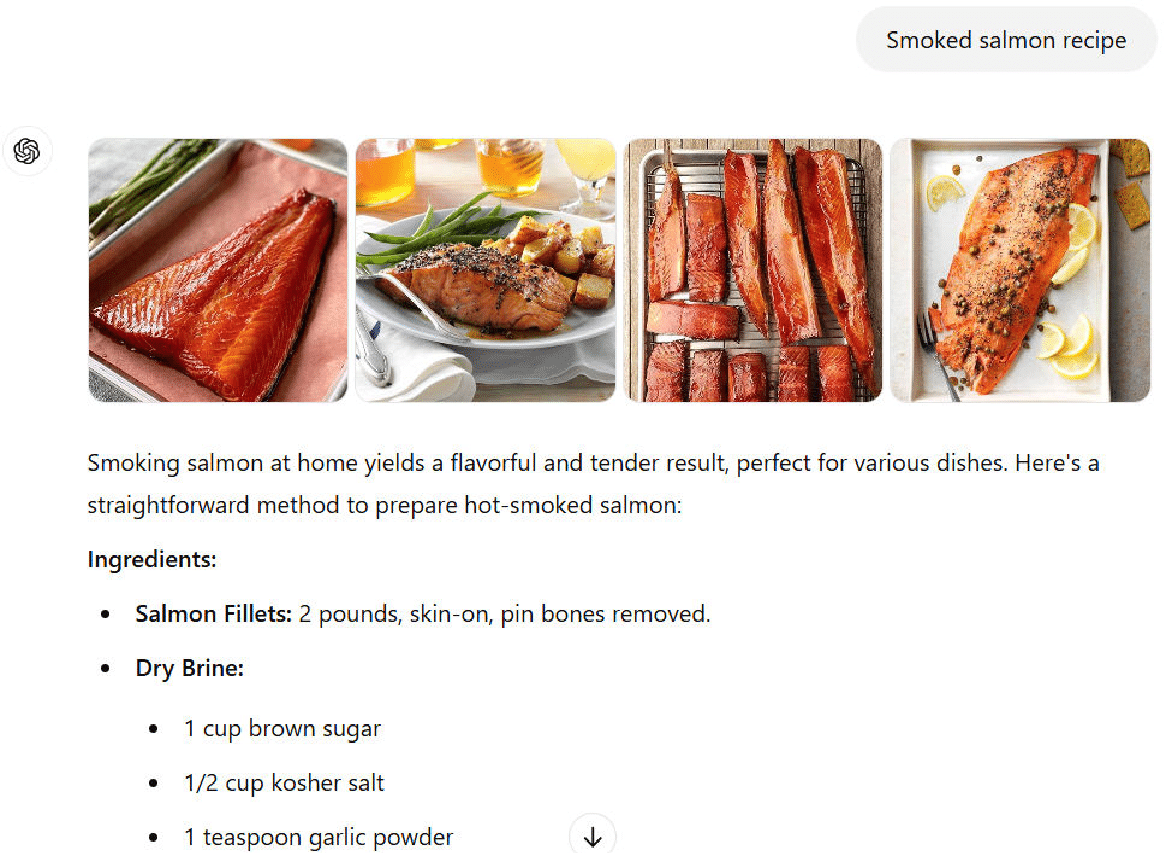


I’ve included the first three screens of the response (out of four), and here you will see that ChatGPT search provides one specific recipe from a site called Honest Food.
In addition, I see some things that don’t align with my experience.
For example, this write-up recommends cooking the salmon to 140 degrees. That’s already beginning to dry the salmon a bit.
From what I see on the Honest Food site, they suggest a range of possible temperatures starting from as low as 125.
In contrast, Google offers multiple recipes that you can access from the SERPs:
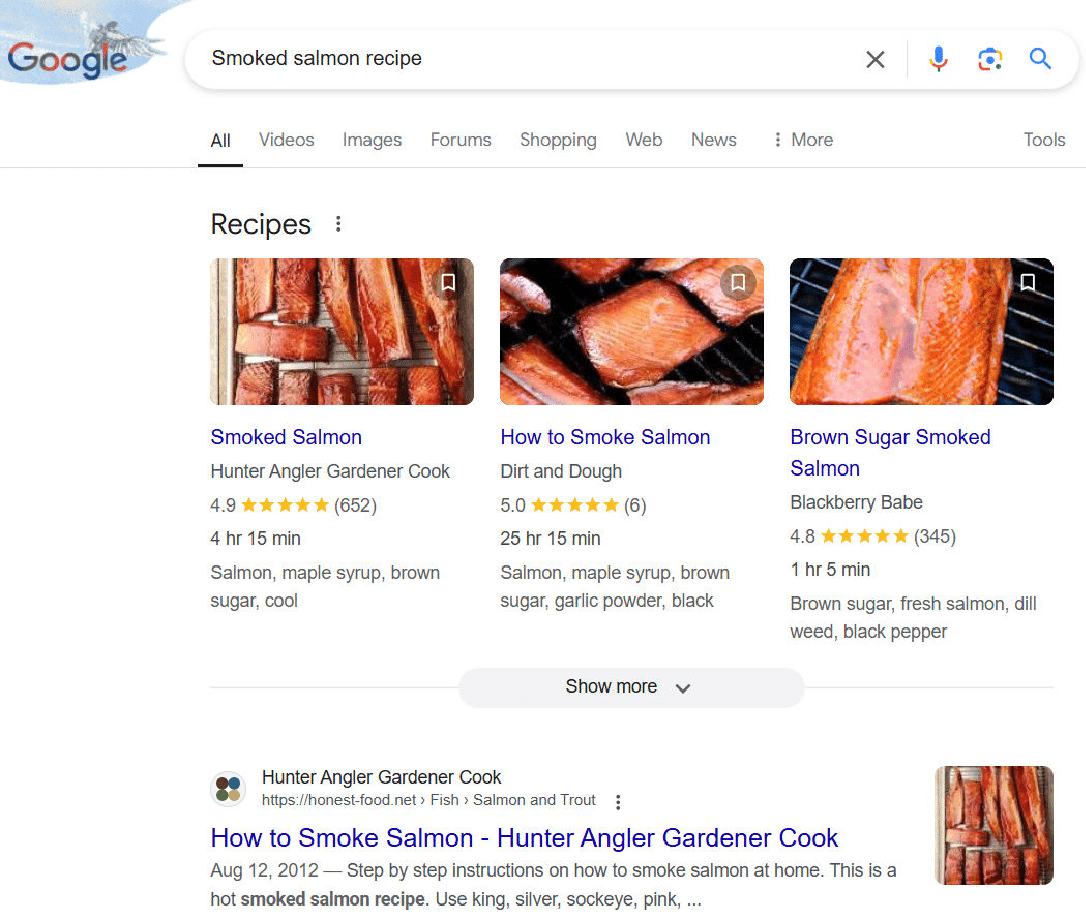
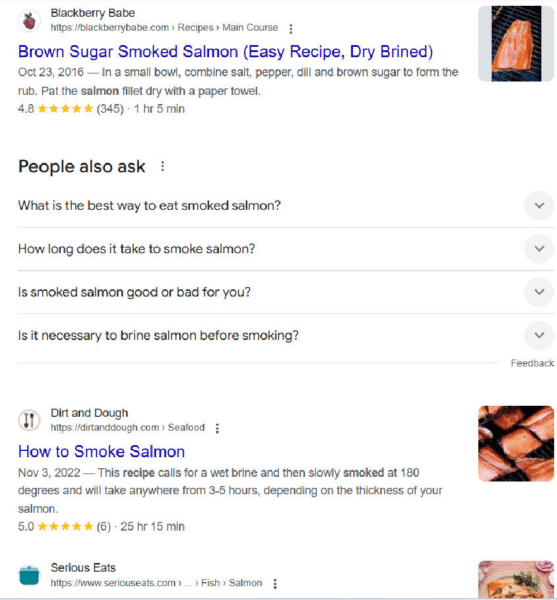
This is an example of a query that I scored in Google’s favor, as having multiple options is what I believe most searchers will want.
The scores I assigned were:
- ChatGPT search: 4.00.
- Google: 8.00.
Types of problems
Next, we’ll examine the types of things that can go wrong. I looked for these issues while scoring the results.
The analysis noted where problems that generative AI tools are known for were found and potential areas of weakness in Google’s SERPs.
These included:
- Errors.
- Omissions.
- Weaknesses.
- Incomplete coverage.
- Insufficient follow-on resources.
Problem type: Errors
This is what the industry refers to as “hallucinations,” meaning that the information provided is simply wrong.
Sometimes errors aren’t necessarily your money or your life situations, but they still give the user incorrect information.
Consider how ChatGPT search responds to a query asking about the NFL’s overtime rules:

Notice the paragraph discussing how Sudden Death works. Unfortunately, it’s not correct.
It doesn’t account for when the first team that possesses the ball kicks a field goal, in which case they could win the game if the second team doesn’t score a field goal.
If the second team scores a field goal, this will tie the game.
In this event, it’s only after the field goal by the second team that the next score wins the game.
This nuance is missed by ChatGPT search.
Note: The information on the NFL Operations page that ChatGPT search used as a source is correct.
Google’s AI Overview also has an error in it:
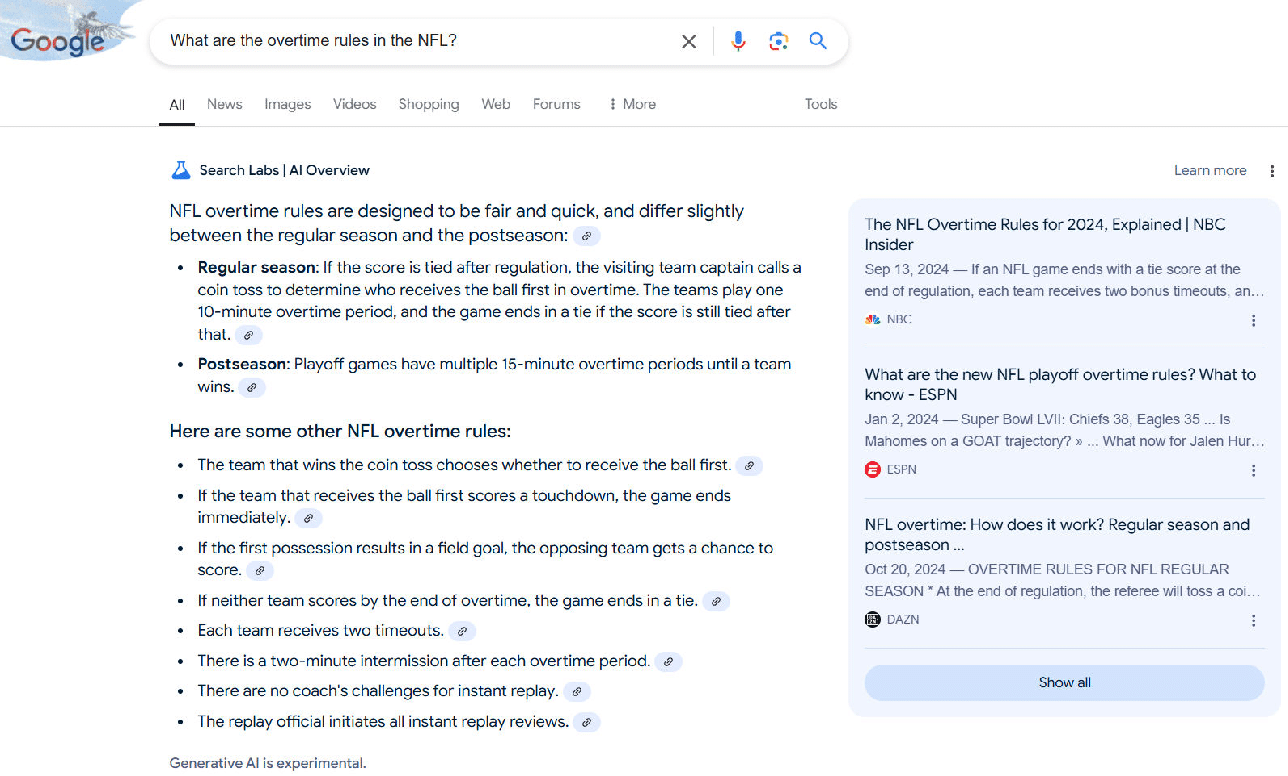
In the second line, where Google outlines “some other NFL overtime rules,” it notes that the same ends if the first team to possess the ball scores a touchdown.
This is true for regular season games but not true in the postseason, where both teams always get an opportunity to possess the ball.
Scores were as follows:
- ChatGPT search: 3.00.
- Google: 4.00.
Problem type: Omissions
This type of issue arises when important information that belongs in the response is left out.
Here is an example where ChatGPT search does this:

Under Pain Management, there is no mention of Tylenol as a part of a pain management regimen.
This is an unfortunate omission, as many people use only a mix of Tylenol and Ibuprofen to manage the pain after a meniscectomy.
Scores were as follows:
- ChatGPT search: 6.00.
- Google: 5.00.
Problem type: Weaknesses
I used weaknesses to cover cases where aspects of the result could have been more helpful to the searcher but where the identified issue couldn’t properly be called an error or omission.
Here is an example of an AI Overview that illustrates this:
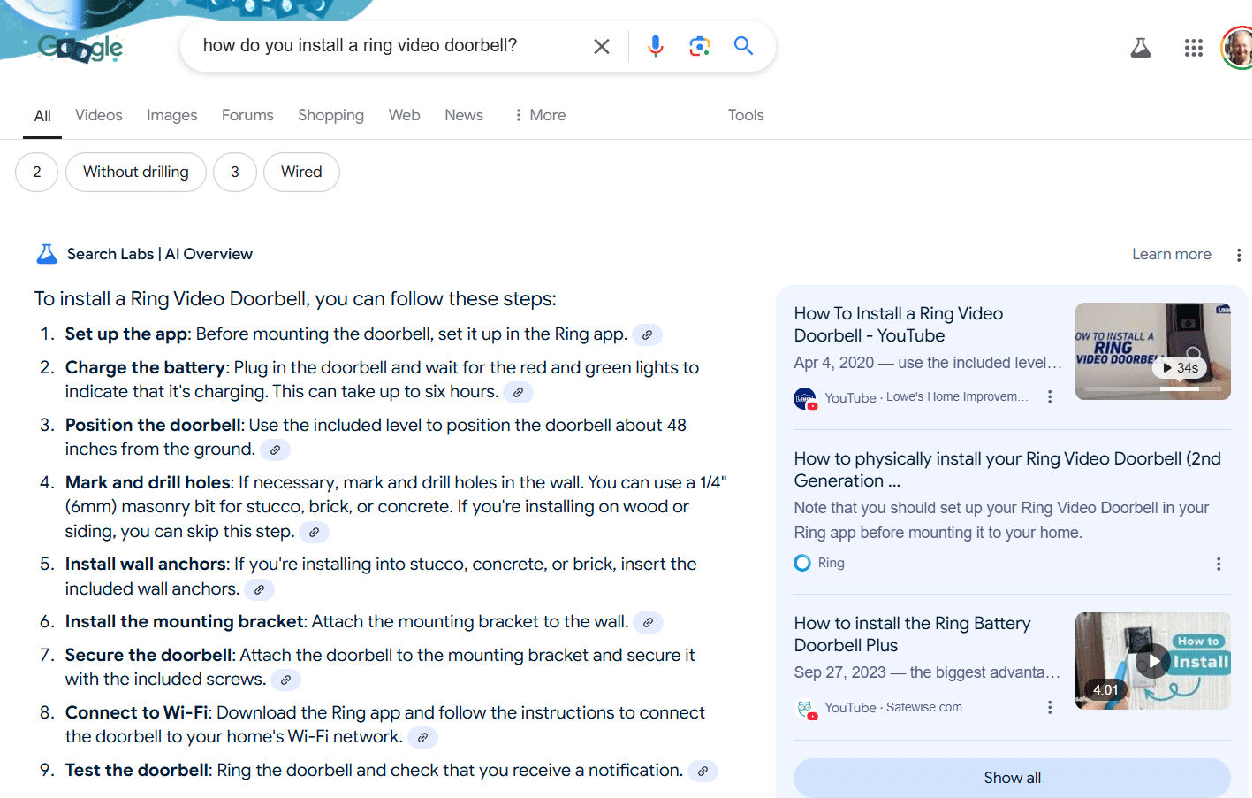
The weakness of this outline is that it makes the most sense to charge the battery as the first step.
Since it takes up to 6 hours to complet,e it’s not that useful to set up the app before completing this step.
Here is how I scored these two responses:
- ChatGPT search: 3.00.
- Google: 5.00.
Problem type: Incomplete coverage
This category is one that I used to identify results that failed to cover a significant user need for a query.
Note that “significant” is subjective, but I tried to use this only when many users would need a second query to get what they were looking for.
Here is an example of this from a Google SERP.

The results are dominated by Google Shopping (as shown above).
Below what I’ve shown, Google has two ads offering online buying opportunities and two pages from the Riedl website.
This result will leave a user who needs the glasses today and therefore wants to shop locally without an answer to their question.
ChatGPT search did a better job with this query as it listed both local retailers and online shopping sites.
Scores for this query:
- ChatGPT search: 6.00.
- Google: 4.00.
Problem type: Insufficient follow-on resources
As discussed in “How query sessions work” earlier in this article, it’s quite common that users will try a series of queries to get all the information they’re looking for.
As a result, a great search experience will facilitate that process.
This means providing a diverse set of resources that makes it easy for users to research and find what they want/need. When these aren’t easily accessed it offers them a poor experience.
As an example, let’s look at how ChatGPT search responds to the query “hotels in San Diego”:
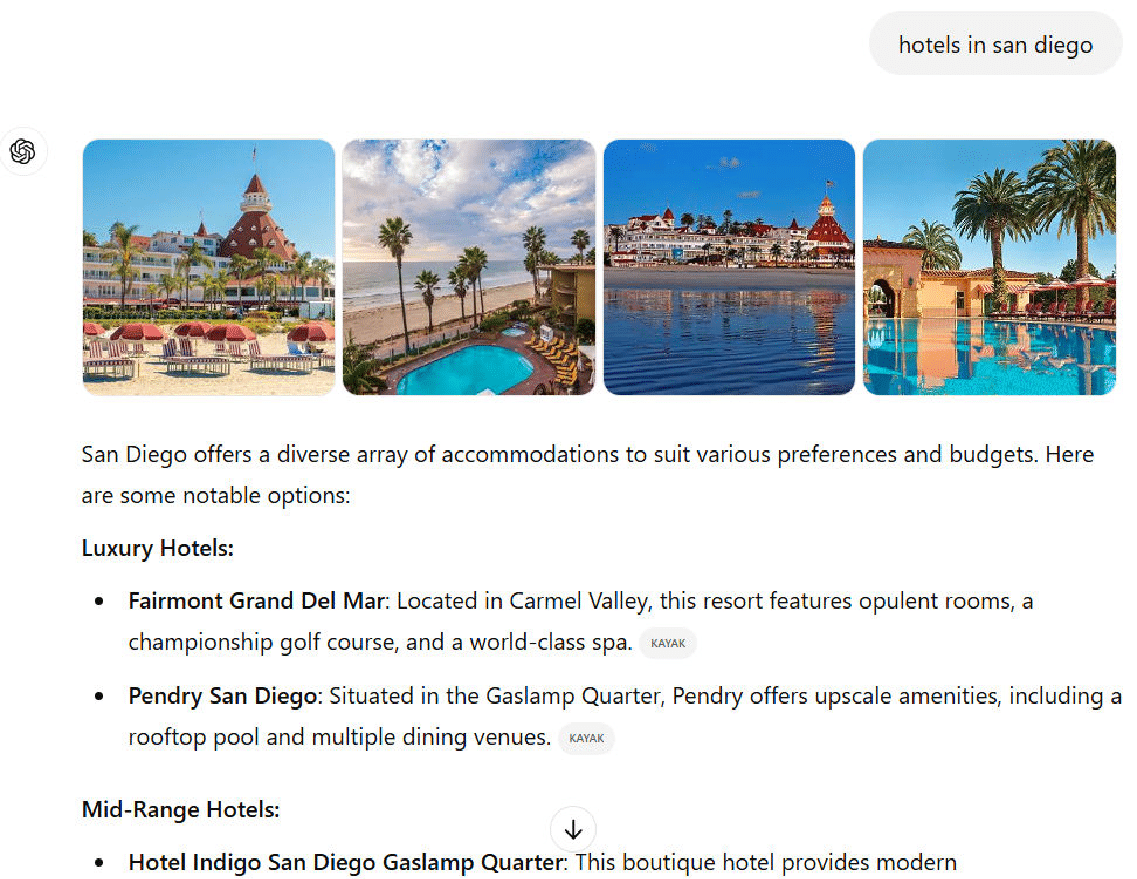


While this provides 11 hotels as options, there are far more than this throughout the San Diego area.
It’s also based on a single source: Kayak.
The user can click through to the Kayak site to get a complete list, but other resources aren’t made available to the user.
In contrast, Google’s results show many different sites that can be used to find what they want. The scores I assigned to the competitors for this one were:
- ChatGPT search: 3.00.
- Google: 6.00.
The winner?
It’s important to note that this analysis is based on a small sample of 62 queries, which is far too limited to draw definitive conclusions about all search scenarios.
A broader takeaway can be gained by reviewing the examples above to see where each platform tends to perform better.
Here’s a breakdown of category winners:
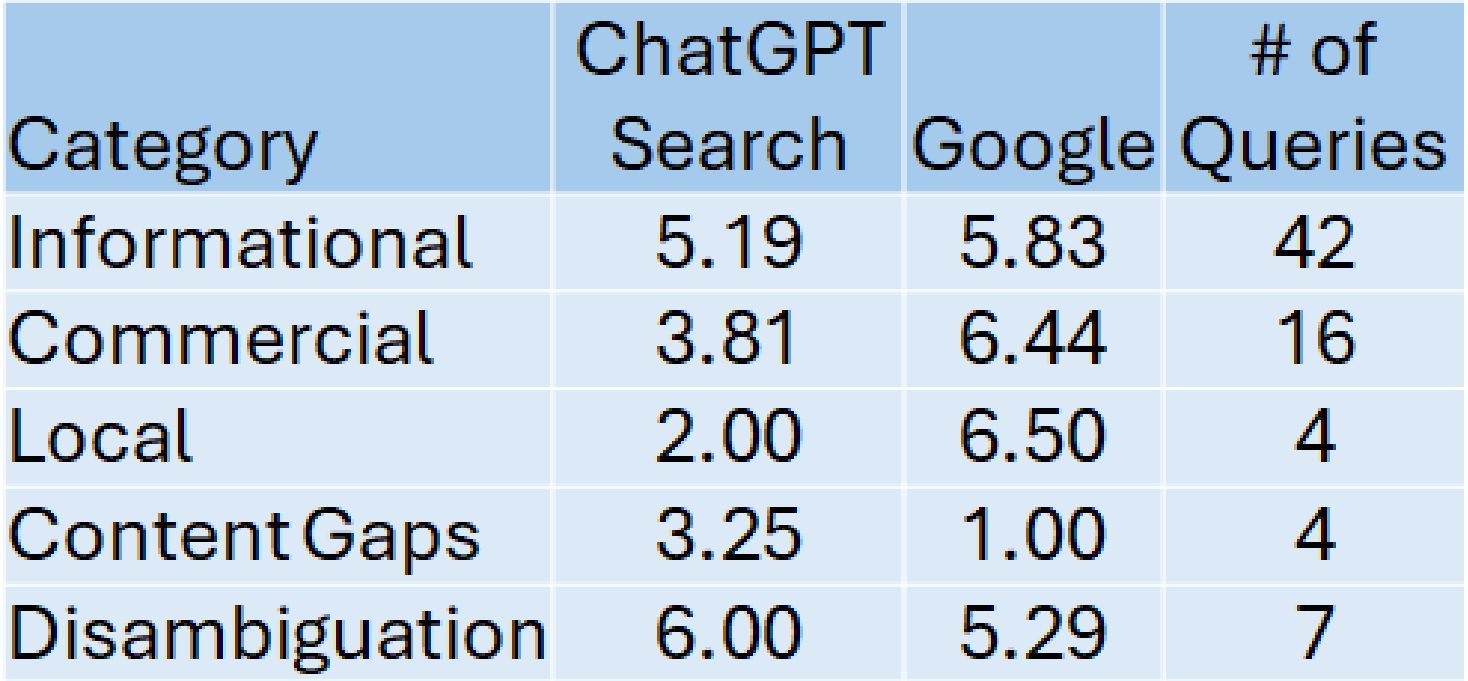
1. Informational queries
- Queries: 42
- Winner: Google
- Google’s average score: 5.83
- ChatGPT search’s average score: 5.19
Google’s slight edge aligns with its strong track record for informational searches.
However, ChatGPT Search performed respectably, despite challenges with errors, omissions, and incomplete responses.
2. Content gap analysis
- Winner: ChatGPT Search
- ChatGPT search’s average score: 3.25
- Google’s average score: 1.0
- ChatGPT Search excels in content gap analysis and related tasks, making it particularly useful for content creators. Winning use cases include:
- Content gap analysis
- Standalone content analysis
- Comparing direct or indirect SERP competitors
- Suggesting article topics and outlines
- Identifying facts/statistics with sources
- Recommending FAQs for articles
While ChatGPT search outperformed Google in this category, its lower overall score highlights areas where improvements are needed, such as accuracy.
3. Navigational queries
- Winner: Google
Navigational queries were excluded from the test since they typically don’t require detailed text responses.
Google’s dominance in this category is assumed based on its straightforward, website-focused results.
4. Local search queries
- Winner: Google
- Google’s average score: 6.25
- ChatGPT search’s average score: 2.0
Google’s extensive local business data, combined with tools like Google Maps and Waze, ensures its superiority in this category.
5. Commercial queries
- Winner: Google
- Google’s average score: 6.44
- ChatGPT search’s average score: 3.81
This category, comprising 16 queries, favored Google due to its stronger capabilities in showcasing product and service-related results.
6. Disambiguation queries
- Winner: ChatGPT search
- ChatGPT search’s average score: 6.0
- Google’s average score: 5.29
ChatGPT Search edged out Google by more effectively presenting multiple definitions or interpretations for ambiguous terms, providing users with greater clarity.
These scores are summarized in the following table:
Summary
After a detailed review of 62 queries, I still see Google as the better solution for most searches.
ChatGPT search is surprisingly competitive when it comes to informational queries, but Google edged ChatGPT search out here too.
Note that 62 queries are a tiny sample when considered against the scope of all search.
Nonetheless, as you consider your search plans going forward, I’d advise you to do a segmented analysis like what I did before deciding which platform is the better choice for your projects.
source https://searchengineland.com/chatgpt-search-vs-google-analysis-449676



0 Comments